Showing posts with label fedora. Show all posts
Showing posts with label fedora. Show all posts
Sunday, 8 June 2014
Postgresql Backup To Amazon S3 On OpenShift Origin
To move forward, you need to backup. Backing up your production data is critical and with Postgresql, you can backup WAL (Write Ahead Log) archives and this post gives you steps to accomplish for backing up postgresql WALs to Amazon S3 on your OpenShift Origin using WAL-E.
WAL-E is a great tool that simplifies backup of postgresql by performing continuous archiving of PostgreSQL WAL files and base backups. Enough blabbering, you can reach out technical docs on how WAL works. I'll just mention series of commands and steps necessary for sending WAL archives to AWS S3 bucket.
On the node containing application with postgresql cartridge, run the following commands:
Then, edit the postgresql configuration file so as to turn on wal archiving. You need to find the right container for your postgresql in /var/lib/openshift (Its quite trivial if you know OpenShift basics).
Finally, you need to ensure that you are taking base backups periodically which can be achieved by utilizing cron cartridge. Clone the repo, add the following file and push to the application.
Make sure you use the OPENSHIFT_POSTGRESQL_DIR env-var or some other env-var that does not have two forward slashes adjacently since WAL-E hates it.
This should help you keep your data backed up regularly and you can enjoy beers.
Read more...
WAL-E is a great tool that simplifies backup of postgresql by performing continuous archiving of PostgreSQL WAL files and base backups. Enough blabbering, you can reach out technical docs on how WAL works. I'll just mention series of commands and steps necessary for sending WAL archives to AWS S3 bucket.
On the node containing application with postgresql cartridge, run the following commands:
$ yum install python-pip lzop pv $ rpm -Uvh ftp://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/p_conrad:/branches/Fedora_19/x86_64/daemontools-0.76-3.1.x86_64.rpm $ pip install wal-e $ umask u=rwx,g=rx,o= $ mkdir -p /etc/wal-e.d/env $ echo "secret-key-content" > /etc/wal-e.d/env/AWS_SECRET_ACCESS_KEY $ echo "access-key" > /etc/wal-e.d/env/AWS_ACCESS_KEY_ID $ echo 's3://backup/production/pgsql' > \ /etc/wal-e.d/env/WALE_S3_PREFIX $ chmod -R 765 /etc/wal-e.d/
Then, edit the postgresql configuration file so as to turn on wal archiving. You need to find the right container for your postgresql in /var/lib/openshift (Its quite trivial if you know OpenShift basics).
$ vi YOUR_OO_CONTAINER/postgresql/data/postgresql.conf
wal_level = archive # hot_standby in 9.0 is also acceptable
archive_mode = on
archive_command = 'envdir /etc/wal-e.d/env wal-e wal-push %p'
archive_timeout = 60
archive_mode = on
archive_command = 'envdir /etc/wal-e.d/env wal-e wal-push %p'
archive_timeout = 60
Finally, you need to ensure that you are taking base backups periodically which can be achieved by utilizing cron cartridge. Clone the repo, add the following file and push to the application.
$ vi .openshift/cron/daily/postgres-backup
#!/bin/bash
if [ $OPENSHIFT_POSTGRESQL_DIR ]; then
/usr/bin/envdir /etc/wal-e.d/env /bin/wal-e backup-push ${OPENSHIFT_POSTGRESQL_DIR}data
fi
$ git add .openshift/cron/daily/postgres-backup
$ git commit -m "Added pg cron script"
$ git push origin master
Make sure you use the OPENSHIFT_POSTGRESQL_DIR env-var or some other env-var that does not have two forward slashes adjacently since WAL-E hates it.
This should help you keep your data backed up regularly and you can enjoy beers.
Read more...
Bookmark this post: | 
|
Thursday, 5 June 2014
Setting Up JVM Heap Size In JBoss OpenShift Origin
Openshift is an awesome technology and have fell in love with it recently. In this post, I will talk about how we can set JVM Heap Size for your application using Jboss cartridge.
If you look into the content of the standalone.conf located at $OPENSHIFT_JBOSSEAP_DIR/bin, you can see that JVM_HEAP_RATIO is set to 0.5 if it is not already set.
And, later this ratio is used to calculate the max_heap so as to inject the maximum heap size in jboss java process. You can see how gear memory size is used to calculate the value of heap size. This is the very reason why the default installation allocates half of total gear memory size.
OpenShift keeps its number of environment variables inside /var/lib/openshift/OPENSHIFT_GEAR_UUID/.env so what I did was SSH to my OO node and run the command below (you should replace your gear's UUID):
Alternatively, rhc set-env JVM_HEAP_RATIO=0.7 -a appName should also work but I have not tried it.
Read more...
If you look into the content of the standalone.conf located at $OPENSHIFT_JBOSSEAP_DIR/bin, you can see that JVM_HEAP_RATIO is set to 0.5 if it is not already set.
if [ -z "$JVM_HEAP_RATIO" ]; then
JVM_HEAP_RATIO=0.5
And, later this ratio is used to calculate the max_heap so as to inject the maximum heap size in jboss java process. You can see how gear memory size is used to calculate the value of heap size. This is the very reason why the default installation allocates half of total gear memory size.
max_memory_mb=${OPENSHIFT_GEAR_MEMORY_MB}
max_heap=$( echo "$max_memory_mb * $JVM_HEAP_RATIO" | bc | awk '{print int($1+0.5)}')
OpenShift keeps its number of environment variables inside /var/lib/openshift/OPENSHIFT_GEAR_UUID/.env so what I did was SSH to my OO node and run the command below (you should replace your gear's UUID):
$ echo -n 0.7 > /var/lib/openshift/52e8d31bfa7c355caf000039/.env/JVM_HEAP_RATIO
Alternatively, rhc set-env JVM_HEAP_RATIO=0.7 -a appName should also work but I have not tried it.
Read more...
Bookmark this post: |
|
Friday, 11 April 2014
Patching Your OpenShift Origin Against Heartbleed vulnerability
Recently the heartbleed bug was exposed which existed in all the services that used OpenSSL 1.0.1 through 1.0.1f (inclusive) for years already. This weakness allows stealing the information protected, under normal conditions, by the SSL/TLS encryption used to secure the Internet by reading the memory of the system without need of any kind of access.
I've been administering OpenShift applications recently and this post outlines the measures I took to secure the OpenShift applications from this critical vulnerability.
In order to check if you are vulnerable or not, you can either check OpenSSL version:
Alternatively, you can use one of the online tools or the offline python tool to check if you are vulnerable or not.
Note that in case of OpenShift origin, you will have to update the OpenSSL package in brokers and nodes such that all the OpenShift apps are secure.
Once completed, verify the installation of patched version:
We'll have to restart the proxy systems (node-proxy) for the nodes for the effect of the patch. In fact, we will have to restart all the services that use the vulnerable OpenSSL versions.
I hope this helps :)
Read more...
I've been administering OpenShift applications recently and this post outlines the measures I took to secure the OpenShift applications from this critical vulnerability.
In order to check if you are vulnerable or not, you can either check OpenSSL version:
# openssl version -a
OpenSSL 1.0.1e-fips 11 Feb 2013
built on: Wed Jan 8 07:20:55 UTC 2014
platform: linux-x86_64
OpenSSL 1.0.1e-fips 11 Feb 2013
built on: Wed Jan 8 07:20:55 UTC 2014
platform: linux-x86_64
Alternatively, you can use one of the online tools or the offline python tool to check if you are vulnerable or not.
Note that in case of OpenShift origin, you will have to update the OpenSSL package in brokers and nodes such that all the OpenShift apps are secure.
# yum install -y openssl
Once completed, verify the installation of patched version:
# openssl version -a
OpenSSL 1.0.1e-fips 11 Feb 2013
built on: Tue Apr 8 00:29:11 UTC 2014
platform: linux-x86_64
# rpm -q --changelog openssl | grep CVE-2014-0160
- pull in upstream patch for CVE-2014-0160
OpenSSL 1.0.1e-fips 11 Feb 2013
built on: Tue Apr 8 00:29:11 UTC 2014
platform: linux-x86_64
# rpm -q --changelog openssl | grep CVE-2014-0160
- pull in upstream patch for CVE-2014-0160
We'll have to restart the proxy systems (node-proxy) for the nodes for the effect of the patch. In fact, we will have to restart all the services that use the vulnerable OpenSSL versions.
# systemctl restart openshift-node-web-proxy.service
# /bin/systemctl reload httpd.service
# /bin/systemctl reload httpd.service
I hope this helps :)
Read more...
Bookmark this post: |
|
Monday, 18 November 2013
Install HTTrack On CentOS
Since I could not find the rpm in the repo, here is the quick How To to install HTTrack website copier on CentOS.
This should do all. If you wish not to install zlib compression support, you can skip the first step and run the configure as ./configure --without-zlib. I hope this helps :)
Read more...
$ yum install zlib-devel
$ wget http://download.httrack.com/cserv.php3?File=httrack.tar.gz -O httrack.tar.gz
$ tar xvfz httrack.tar.gz
$ cd httrack-3.47.27
$ ./configure
$ make && sudo make install
$ wget http://download.httrack.com/cserv.php3?File=httrack.tar.gz -O httrack.tar.gz
$ tar xvfz httrack.tar.gz
$ cd httrack-3.47.27
$ ./configure
$ make && sudo make install
This should do all. If you wish not to install zlib compression support, you can skip the first step and run the configure as ./configure --without-zlib. I hope this helps :)
Read more...
Bookmark this post: |
|
Thursday, 27 June 2013
Manual Sun Java Installation In Linux
Be it be multiple installations of java or be it be custom server, you might run into the necessity of manually installing java. This tutorial will provide step by step commands for installing java manually in linux.
Though the process was done on CentOS, it should work for most linux systems with or without slightest modifications. The process below installs Sun Java and configures Sun Java to be the default java to be used. Below are the steps I took to install and configure java in my system:
If you wish to reconfigure the default java, you can run alternatives as below & choose the appropriate option:
I hope this helps :)
Read more...
Though the process was done on CentOS, it should work for most linux systems with or without slightest modifications. The process below installs Sun Java and configures Sun Java to be the default java to be used. Below are the steps I took to install and configure java in my system:
$ cd /opt/java
$ wget http://download.oracle.com/otn-pub/java/jdk/6u45-b15/jdk-6u45-linux-i586.tar.gz
$ tar xvfz jdk-6u45-linux-i586.tar.gz
$ echo 'export JAVA_HOME=/opt/java/jdk1.6.0_45' > /etc/profile.d/sun-jdk.sh
$ echo 'export PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile.d/sun-jdk.sh
$ alternatives --install /usr/bin/java java /opt/java/jdk1.6.0_45/bin/java 2
$ java -version
$ wget http://download.oracle.com/otn-pub/java/jdk/6u45-b15/jdk-6u45-linux-i586.tar.gz
$ tar xvfz jdk-6u45-linux-i586.tar.gz
$ echo 'export JAVA_HOME=/opt/java/jdk1.6.0_45' > /etc/profile.d/sun-jdk.sh
$ echo 'export PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile.d/sun-jdk.sh
$ alternatives --install /usr/bin/java java /opt/java/jdk1.6.0_45/bin/java 2
$ java -version
java version "1.6.0_45" Java(TM) SE Runtime Environment (build 1.6.0_45-b06) Java HotSpot(TM) 64-Bit Server VM (build 20.45-b01, mixed mode)
If you wish to reconfigure the default java, you can run alternatives as below & choose the appropriate option:
$ alternatives --config java
Read more...
Bookmark this post: |
|
Friday, 23 November 2012
Video Transcoding With HandBrake In Linux
HandBrake is a GPL-licensed, multiplatform, multithreaded video transcoder available for major platforms: linux, mac, and windows. HandBrake converts video from nearly any format to a handful of modern ones.

Handbrake can save output in two containers, MP4 and MKV and I've been using it as a MKV transcoder for a while and I'm quite satisfied with it. Even though the official wiki says its not a ripper, I can see it to be quite useful DVD ripper.
Handbrake is available in CLI (HandBrakeCLI) and GUI (ghb) mode. Hence this offers the flexibility to choose the appropriate version according to your linux personality. As of now, we can install HandBrake from PPA and the latest version is v. 0.9.8 released back in July this year.
HandBrake can be installed from PPA. Issue the following commands in your terminal
Or if you wish to install the GUI version, type:
I recommend using the CLI version since you can transcode/convert videos much more efficiently if you use the CLI version. But if you are not comfortable with the command line interfaces, the GUI version of HandBrake is also quite good.

Only problem I have felt is the naming convention of the commands for both the GUI and CLI versions of the tool. In order to run two versions of this tool, you need to type HandBrakeCLI for CLI version and ghb for the GUI version. The problem here is with the naming convention for the binaries. I mean, the names handbrake-cli and handbrake-gtk would be more straightforward than these badly chosen names. Otherwise, the tool does pretty good job of video conversion and can be good alternative if you are not comfortable with ffmpeg. Note that ffmpeg is also capable of video conversions of different formats and is a great tool. :)
Read more...
Handbrake can save output in two containers, MP4 and MKV and I've been using it as a MKV transcoder for a while and I'm quite satisfied with it. Even though the official wiki says its not a ripper, I can see it to be quite useful DVD ripper.
Handbrake is available in CLI (HandBrakeCLI) and GUI (ghb) mode. Hence this offers the flexibility to choose the appropriate version according to your linux personality. As of now, we can install HandBrake from PPA and the latest version is v. 0.9.8 released back in July this year.
HandBrake can be installed from PPA. Issue the following commands in your terminal
$ sudo add-apt-repository ppa:stebbins/handbrake-releases
$ sudo apt-get update
$ sudo apt-get install handbrake-cli
$ sudo apt-get update
$ sudo apt-get install handbrake-cli
Or if you wish to install the GUI version, type:
$ sudo apt-get install handbrake-gtk
I recommend using the CLI version since you can transcode/convert videos much more efficiently if you use the CLI version. But if you are not comfortable with the command line interfaces, the GUI version of HandBrake is also quite good.

Only problem I have felt is the naming convention of the commands for both the GUI and CLI versions of the tool. In order to run two versions of this tool, you need to type HandBrakeCLI for CLI version and ghb for the GUI version. The problem here is with the naming convention for the binaries. I mean, the names handbrake-cli and handbrake-gtk would be more straightforward than these badly chosen names. Otherwise, the tool does pretty good job of video conversion and can be good alternative if you are not comfortable with ffmpeg. Note that ffmpeg is also capable of video conversions of different formats and is a great tool. :)
Read more...
Bookmark this post: |
|
Saturday, 3 November 2012
Make Your Linux Read Papers For You
Fed up of reading text files and PDF papers? Is you eye power degrading day by day and can't hold even few minutes on screen? Don't worry, you can easily make your linux system speak and read all those papers for you.
There are several text to speech tools available for linux but in this post, I will be using festival, a Text-to-speech (TTS) tool written in C++. Also, Ubuntu and its derivation are most likely to include by default espeak, a multi-lingual software speech synthesizer.
For ubuntu and debian based system, type the following to install festival:
Moreover, you can also install a pidgin plugin that uses festival:
For now, you just need to install festival. Once you have installed festival, you can make it read text files for you. If you go through the online manual of festival, it says:
"Festival works in two fundamental modes, command mode and text-to-speech mode (tts-mode). In command mode, information (in files or through standard input) is treated as commands and is interpreted by a Scheme interpreter. In tts-mode, information (in files or through standard input) is treated as text to be rendered as speech. The default mode is command mode, though this may change in later versions."
To read a text file, you can use the command below:
The festival will start in text-to-speech (tts) mode and will read your text files for you. But now, we want to read PDF files and if you try to read PDF files directly (festival --tts paper.pdf), festival is most likely to speak the cryptic terms since it actually reads the content of PDF including its header (You know PDF is different than simple text file). So we will use a pdftotext command to convert our pdf file and then pipe the output to the festival so that festival reads the PDF files for us. You can use the syntax as below to read PDF files.
If you want to skip all those table of contents and prefaces or if you are in the middle of PDF, you can use the switches of pdftotext to change the starting and ending pages. For example, if I wish to read page 10 - 14 of a PDF, I would do:
Enjoy learning. I hope this post helps you ;)
Read more...
There are several text to speech tools available for linux but in this post, I will be using festival, a Text-to-speech (TTS) tool written in C++. Also, Ubuntu and its derivation are most likely to include by default espeak, a multi-lingual software speech synthesizer.
For ubuntu and debian based system, type the following to install festival:
samar@samar-Techgaun:~$ sudo apt-get install festival
Moreover, you can also install a pidgin plugin that uses festival:
samar@samar-Techgaun:~$ sudo apt-get install pidgin-festival
For now, you just need to install festival. Once you have installed festival, you can make it read text files for you. If you go through the online manual of festival, it says:
"Festival works in two fundamental modes, command mode and text-to-speech mode (tts-mode). In command mode, information (in files or through standard input) is treated as commands and is interpreted by a Scheme interpreter. In tts-mode, information (in files or through standard input) is treated as text to be rendered as speech. The default mode is command mode, though this may change in later versions."
To read a text file, you can use the command below:
samar@samar-Techgaun:~$ festival --tts mypaper.txt
The festival will start in text-to-speech (tts) mode and will read your text files for you. But now, we want to read PDF files and if you try to read PDF files directly (festival --tts paper.pdf), festival is most likely to speak the cryptic terms since it actually reads the content of PDF including its header (You know PDF is different than simple text file). So we will use a pdftotext command to convert our pdf file and then pipe the output to the festival so that festival reads the PDF files for us. You can use the syntax as below to read PDF files.
samar@samar-Techgaun:~$ pdftotext paper.pdf - | festival --tts
If you want to skip all those table of contents and prefaces or if you are in the middle of PDF, you can use the switches of pdftotext to change the starting and ending pages. For example, if I wish to read page 10 - 14 of a PDF, I would do:
samar@samar-Techgaun:~$ pdftotext -f 10 -l 14 paper.pdf - | festival --tts
Enjoy learning. I hope this post helps you ;)
Read more...
Bookmark this post: |
|
Saturday, 27 October 2012
Linux Cat Command Examples
The cat command displays the content of file on the standard output. If multiple files are specified, the contents of all files will be concatenated and then displayed on the standard output. Likewise, if no file is specified, it will assume standard input (keyboard input) as the input to the command. The Ctrl + d is the shortcut used to save the contents in the appropriate output placeholder specified and exit the cat command.
Print content of file in standard output
samar@samar-Techgaun:~$ cat workers.txt List of workers, designations & salary (in K): Kshitiz Director 30 Bikky Manager 20 Abhis Sweeper 10 Rajesh Guard 12
Print line numbers
samar@samar-Techgaun:~$ cat -n workers.txt
1 List of workers, designations & salary (in K):
2 Kshitiz Director 30
3 Bikky Manager 20
4
5
6 Abhis Sweeper 10
7 Rajesh Guard 12
Print line numbers for non-empty lines only
samar@samar-Techgaun:~$ cat -b workers.txt
1 List of workers, designations & salary (in K):
2 Kshitiz Director 30
3 Bikky Manager 20
4 Abhis Sweeper 10
5 Rajesh Guard 12
Create a new file
samar@samar-Techgaun:~$ cat > newfile.txt We can create text files using cat command once u finish writing, press ctrl+d to save file ^d
Display content of multiple files
samar@samar-Techgaun:~$ cat workers.txt newfile.txt List of workers, designations & salary (in K): Kshitiz Director 30 Bikky Manager 20 Abhis Sweeper 10 Rajesh Guard 12 We can create text files using cat command once u finish writing, press ctrl+d to save file
Combine multiple files to new file
samar@samar-Techgaun:~$ cat workers.txt newfile.txt > concat.txt samar@samar-Techgaun:~$ cat concat.txt List of workers, designations & salary (in K): Kshitiz Director 30 Bikky Manager 20 Abhis Sweeper 10 Rajesh Guard 12 We can create text files using cat command once u finish writing, press ctrl+d to save file
Append data to existing file
samar@samar-Techgaun:~$ cat >> newfile.txt New line added ^d samar@samar-Techgaun:~$ cat newfile.txt We can create text files using cat command once u finish writing, press ctrl+d to save file New line added
Alternatively, you can use the syntax below if you wish to create new file combining the content of already existing file and standard input.
samar@samar-Techgaun:~$ cat newfile.txt - > myfile thanks for everything ^d samar@samar-Techgaun:~$ cat myfile We can create text files using cat command once u finish writing, press ctrl+d to save file New line added thanks for everything
Another possibility is to combine two text files with data from standard input (keyboard) in-between the contents of these two text files.
samar@samar-Techgaun:~$ cat workers.txt - newfile.txt > myfile ---------------------------------- ^d samar@samar-Techgaun:~$ cat myfile List of workers, designations & salary (in K): Kshitiz Director 30 Bikky Manager 20 Abhis Sweeper 10 Rajesh Guard 12 ---------------------------------- We can create text files using cat command once u finish writing, press ctrl+d to save file New line added
Display $ sign at the end of each line
samar@samar-Techgaun:~$ cat -E workers.txt List of workers, designations & salary (in K):$ Kshitiz Director 30$ Bikky Manager 20$ $ $ Abhis Sweeper 10$ Rajesh Guard 12$
Display ^I sign instead of TABs
samar@samar-Techgaun:~$ cat -T workers.txt List of workers, designations & salary (in K): Kshitiz^IDirector^I30 Bikky^IManager^I^I20 Abhis^ISweeper^I^I10 Rajesh^IGuard^I^I12
Display files with non-printing characters
samar@samar-Techgaun:~$ cat -v /bin/nc
In the example above, the non-printing characters are replaced with ^ and M- notation except for line breaks and TABs. This can be used to display the contents of binary files which would otherwise have shown gibberish text all over the console.
Show contents with tabs, line breaks and non-printing characters
samar@samar-Techgaun:~$ cat -A /bin/nc
The tab will be substituted by ^I, line breaks with $ and non-printing characters with ^ and M- notation. Actually, the -A switch is equivalent to -vET switch.
Supress/squeeze repeated empty lines
samar@samar-Techgaun:~$ cat -s workers.txt List of workers, designations & salary (in K): Kshitiz Director 30 Bikky Manager 20 Abhis Sweeper 10 Rajesh Guard 12
Using -s switch, we can squeeze repeatedly occurring blank lines and replace all the adjacent empty lines with a single empty line in the output. This might be useful to reformat a file with several empty lines in-between (eg. cat -s workers.txt > formatted_workers.txt).
Display last line first
samar@samar-Techgaun:~$ tac workers.txt Rajesh Guard 12 Abhis Sweeper 10 Bikky Manager 20 Kshitiz Director 30 List of workers, designations & salary (in K):
It is the tac, not the cat that is doing the magic but just thought that this is the right place to make a note about this little known command.
Edit: Added here-doc examples. Thanks rho dai for pointing me this.
Parameter substitution using here-document strings
samar@samar-Techgaun:~$ cat > test << TEST samar@samar-Techgaun:~$ I am $USER. My home is $HOME samar@samar-Techgaun:~$ I came here from $OLDPWD samar@samar-Techgaun:~$ TEST samar@samar-Techgaun:~$ cat test I am samar. My home is /home/samar I came here from /home/samar/Downloads
Command expansion example
samar@samar-Techgaun:~$ cat > test << TEST samar@samar-Techgaun:~$ $(ls /) samar@samar-Techgaun:~$ TEST samar@samar-Techgaun:~$ cat test bin boot cdrom dev etc home initrd.img initrd.img.old lib lost+found media mnt opt proc root run sbin selinux srv sys tmp usr var vmlinuz vmlinuz.old
Parameter substitution turned off
samar@samar-Techgaun:~$ cat > test << 'TEST' samar@samar-Techgaun:~$ I am $USER. My home is $HOME samar@samar-Techgaun:~$ I came here from $OLDPWD samar@samar-Techgaun:~$ TEST samar@samar-Techgaun:~$ cat test I am $USER. My home is $HOME I came here from $OLDPWD
Note the difference between the last example and previous two examples. Enclosing the limit string TEST with quotes prevents the substitutions and expansions.
I hope these examples are useful. :)
Read more...
Bookmark this post: |
|
Tuesday, 16 October 2012
Practical ls Command Examples For Fun & Profit
The power of linux lies in the shell through which we can perform complex job in no time. While the directory listing command 'ls' seems to be very simple command, the linux shell provides the power to use switches and pipes to do anything from terminal. Check out this list with practically useful examples using ls.
Any more example that fires up in your mind? Feel free to share over here ;)
Read more...
Display all files including hidden files/folders
ls -a
Display one file/folder per line
ls -1
Count number of files & folders
ls -1 | wc -l
Human readable file sizes (eg. Mb or Gb)
ls -lh
Alphabetically sort the listing
ls -X
Only list the folders in current directory
ls -d */
ls -p | grep /
ls -p | grep /
Display folders in current directory consisting certain patterns
ls -l D* | grep :$
ls -l *a* | grep :$
ls -l *a* | grep :$
List files by descending order of modification time
ls -lt
ls -l --sort=time #alternative long version
ls -l --sort=time #alternative long version
List files by descending order of creation time
ls -lct
List files in reverse order
ls -ltr
ls -l --sort=time --reverse #alternative long version
ls -l --sort=time --reverse #alternative long version
List files in descending order of file size
ls -lSh
ls -lh --sort=size
ls -lSh1 *.avi #find largest AVI file
rm `ls -S1 | head -1` #delete largest file in current folder
ls -lh --sort=size
ls -lSh1 *.avi #find largest AVI file
rm `ls -S1 | head -1` #delete largest file in current folder
List files in ascending order of file size
ls -lShr
ls -lh --sort=size --reverse #alternative long version
ls -lh --sort=size --reverse #alternative long version
Display directories in recursive manner
ls -R
Display the files/folders created today
ls -l --time-style=+%F | grep `date +%F`
Display the files/folders created this year
ls -l --time-style=+%y | grep `date +%y`
Any more example that fires up in your mind? Feel free to share over here ;)
Read more...
Bookmark this post: |
|
Monday, 3 September 2012
Preventing Accidental Overwriting Of Files In Bash Shell
How many times has this happened to you? It used to happen once in a while with me. A Linux user learns to use the redirection operators such as '>' and '>>' but accidental overwriting starts to become common in commands you use and shell scripts you write.
The accidental overwriting of files that happens unintentionally is known as clobbering and it commonly happens while using the '>' redirection operator.
In the above example, the mycmd clobbers any existing data in the myfile file if that file exists already. Worse things may happen sometime. Imagine accidentally typing
instead of possibly using other redirection operators (like >> or <). Thankfully, you could recover /etc/passwd from either /etc/passwd- or /var/backups/passwd.bak if you hadn't rm'd these files.
To prevent such accidental overwriting, we can set the noclobber environment variable. Below is a session of enabling this variable:
As seen above, you have to turn on the noclobber variable using the set -o noclobber command in your shell. However, you might want to intentionally overwrite contents of certain files even when the noclobber is turned on.
Notice the >| in place of your normal > redirection operator. Using this operator, you can however overwrite the existing files even if the noclobber is turned on.
If you want to turn off the noclobber variable, type the following:
You can also permanently turn on the noclobber by the following command:
Moreover, such accidental overwriting can be prevented by enabling the interactive mode which is available in most of the linux commands. For example, you can write the alias for many commands that are likely to cause accidental overwriting. See some examples of aliases below:
You could even keep these aliases in your ~/.bashrc file permanently. Enabling such interactive modes by default in the commands that are more likely to cause accidental overwriting can prevent clobbering in many cases.
I hope this proves useful to you :)
Read more...
The accidental overwriting of files that happens unintentionally is known as clobbering and it commonly happens while using the '>' redirection operator.
samar@Techgaun:~$ mycmd > myfile
In the above example, the mycmd clobbers any existing data in the myfile file if that file exists already. Worse things may happen sometime. Imagine accidentally typing
samar@Techgaun:~$ mycmd > /etc/passwd
instead of possibly using other redirection operators (like >> or <). Thankfully, you could recover /etc/passwd from either /etc/passwd- or /var/backups/passwd.bak if you hadn't rm'd these files.
To prevent such accidental overwriting, we can set the noclobber environment variable. Below is a session of enabling this variable:
samar@Techgaun:~/Desktop/test$ echo "www.techgaun.com" > myfile
samar@Techgaun:~/Desktop/test$ echo "Overwriting techgaun.com" > myfile
samar@Techgaun:~/Desktop/test$ set -o noclobber
samar@Techgaun:~/Desktop/test$ echo "Retrying to overwrite" > myfile
-bash: myfile: cannot overwrite existing file
samar@Techgaun:~/Desktop/test$ echo "Overwriting techgaun.com" > myfile
samar@Techgaun:~/Desktop/test$ set -o noclobber
samar@Techgaun:~/Desktop/test$ echo "Retrying to overwrite" > myfile
-bash: myfile: cannot overwrite existing file
As seen above, you have to turn on the noclobber variable using the set -o noclobber command in your shell. However, you might want to intentionally overwrite contents of certain files even when the noclobber is turned on.
samar@Techgaun:~$ mycmd >| myfile
Notice the >| in place of your normal > redirection operator. Using this operator, you can however overwrite the existing files even if the noclobber is turned on.
If you want to turn off the noclobber variable, type the following:
samar@Techgaun:~$ set +o noclobber
You can also permanently turn on the noclobber by the following command:
samar@Techgaun:~$ echo "set -o noclobber" >> ~/.bashrc
Moreover, such accidental overwriting can be prevented by enabling the interactive mode which is available in most of the linux commands. For example, you can write the alias for many commands that are likely to cause accidental overwriting. See some examples of aliases below:
samar@Techgaun:~$ alias rm=rm -i
samar@Techgaun:~$ alias mv=mv -i
samar@Techgaun:~$ alias mv=mv -i
You could even keep these aliases in your ~/.bashrc file permanently. Enabling such interactive modes by default in the commands that are more likely to cause accidental overwriting can prevent clobbering in many cases.
I hope this proves useful to you :)
Read more...
Bookmark this post: |
|
Sunday, 2 September 2012
How To Search Manual Pages In Linux
Linux system consists of hundreds of binaries, several syscalls, and other stuffs that do have manual page. What if you want to locate or find the commands by searching through the manual pages? In this post, I am going to talk about one such useful command to search through the manual page names and short descriptions.
The command I am talking about is the apropos command. The best way to learn any linux command is to read its corresponding manual and go through the help (-h or --help) so lets poke through the help of apropos itself.
Particularly, the -e switch is quite useful to filter out your search. See the example below:
Each command has its associated short description and the apropos command searches the short description section of appropriate manual page for the provided keyword. You can also specify the search keywords in the form of regular expression for more flexibility. I hope this command counts as useful one :)
Read more...
The command I am talking about is the apropos command. The best way to learn any linux command is to read its corresponding manual and go through the help (-h or --help) so lets poke through the help of apropos itself.
samar@Techgaun:~$ apropos -h
Usage: apropos [OPTION...] KEYWORD...
-d, --debug emit debugging messages
-v, --verbose print verbose warning messages
-e, --exact search each keyword for exact match
-r, --regex interpret each keyword as a regex
-w, --wildcard the keyword(s) contain wildcards
-a, --and require all keywords to match
-l, --long do not trim output to terminal width
-C, --config-file=FILE use this user configuration file
-L, --locale=LOCALE define the locale for this search
-m, --systems=SYSTEM use manual pages from other systems
-M, --manpath=PATH set search path for manual pages to PATH
-s, --section=SECTION search only this section
-?, --help give this help list
--usage give a short usage message
-V, --version print program version
Mandatory or optional arguments to long options are also mandatory or optional
for any corresponding short options.
The --regex option is enabled by default.
Report bugs to cjwatson@debian.org.
Particularly, the -e switch is quite useful to filter out your search. See the example below:
samar@Techgaun:~$ apropos -e tar bf_tar (1) - shell script to write a tar file of a bogofilter direc... bf_tar-bdb (1) - shell script to write a tar file of a bogofilter direc... git-tar-tree (1) - Create a tar archive of the files in the named tree ob... lz (1) - gunzips and shows a listing of a gzip'd tar'd archive mxtar (1) - Wrapper for using GNU tar directly from a floppy disk ptar (1) - a tar-like program written in perl tar (1) - The GNU version of the tar archiving utility tar (5) - format of tape archive files tgz (1) - makes a gzip'd tar archive uz (1) - gunzips and extracts a gzip'd tar'd archive
Each command has its associated short description and the apropos command searches the short description section of appropriate manual page for the provided keyword. You can also specify the search keywords in the form of regular expression for more flexibility. I hope this command counts as useful one :)
Read more...
Bookmark this post: |
|
Monday, 27 August 2012
How To Manually Install Flash Player 11 In Linux
This post will provide a step by step instructions for installing flash player 11 plugin in ubuntu 11.04 and other different versions and distros. This will be helpful for everybody who are having trouble with the software center like I had.
Make sure no firefox process is running and then fire up the terminal and type the following commands in order:
Once you have finished copying the shared object and other necessary files in their respective target directories, you can open the firefox and you're good to go. :)
Read more...
Make sure no firefox process is running and then fire up the terminal and type the following commands in order:
mkdir -p ~/flash && cd ~/flash
wget http://archive.canonical.com/pool/partner/a/adobe-flashplugin/adobe-flashplugin_11.2.202.238.orig.tar.gz
tar -zxvf adobe-flashplugin_11.2.202.238.orig.tar.gz
sudo cp -r libflashplayer.so /usr/lib/firefox/plugins
sudo cp -r usr/* /usr
wget http://archive.canonical.com/pool/partner/a/adobe-flashplugin/adobe-flashplugin_11.2.202.238.orig.tar.gz
tar -zxvf adobe-flashplugin_11.2.202.238.orig.tar.gz
sudo cp -r libflashplayer.so /usr/lib/firefox/plugins
sudo cp -r usr/* /usr
Once you have finished copying the shared object and other necessary files in their respective target directories, you can open the firefox and you're good to go. :)
Read more...
Bookmark this post: |
|
Monday, 13 August 2012
Screen Recording Software Solutions For Linux
Windows users have several options to choose from when it comes to the desktop recording (and only paid ones are good generally) but Linux users have fewer options but robust, simple, and best of all, free and open source desktop screen recording tools that we can trust on.
Below are some of the screen recording tools you might want to try:
recordMyDesktop is a desktop session recorder for GNU/Linux written in C. recordMyDesktop itself is a command-line tool and few GUI frontends are also available for this tool. There are two frontends, written in python with pyGtk (gtk-recordMyDesktop) and pyQt4 (qt-recordMyDesktop). recordMyDesktop offers also the ability to record audio through ALSA, OSS or the JACK audio server. Also, recordMyDesktop produces files using only open formats. These are theora for video and vorbis for audio, using the ogg container.
Installation under debian and ubuntu:
XVidCap is a small tool to capture things going on on an X-Windows display to either individual frames or an MPEG video. It enables you to capture videos off your X-Window desktop for illustration or documentation purposes.It is intended to be a standards-based alternative to tools like Lotus ScreenCam.
Istanbul is a desktop session recorder for the Free Desktop. It records your session into an Ogg Theora video file. To start the recording, you click on its icon in the notification area. To stop you click its icon again. It works on GNOME, KDE, XFCE and others. It was named so as a tribute to Liverpool's 5th European Cup triumph in Istanbul on May 25th 2005.
Vnc2flv is a cross-platform screen recording tool for UNIX, Windows or Mac. It captures a VNC desktop session (either your own screen or a remote computer) and saves as a Flash Video (FLV) file.
Wink is a Tutorial and Presentation creation software, primarily aimed at creating tutorials on how to use software (like a tutor for MS-Word/Excel etc). Using Wink you can capture screenshots, add explanations boxes, buttons, titles etc and generate a highly effective tutorial for your users. It requires GTK 2.4 or higher and unfortunately is just a freeware(could not find any source code for it).
Screenkast is a screen capturing program that records your screen-activities, supports commentboxes and exports to all video formats.
If you got any more suggestions, please drop the comment. :)
Read more...
Below are some of the screen recording tools you might want to try:
recordMyDesktop
recordMyDesktop is a desktop session recorder for GNU/Linux written in C. recordMyDesktop itself is a command-line tool and few GUI frontends are also available for this tool. There are two frontends, written in python with pyGtk (gtk-recordMyDesktop) and pyQt4 (qt-recordMyDesktop). recordMyDesktop offers also the ability to record audio through ALSA, OSS or the JACK audio server. Also, recordMyDesktop produces files using only open formats. These are theora for video and vorbis for audio, using the ogg container.
Installation under debian and ubuntu:
sudo apt-get install gtk-recordmydesktop
XVidCap
XVidCap is a small tool to capture things going on on an X-Windows display to either individual frames or an MPEG video. It enables you to capture videos off your X-Window desktop for illustration or documentation purposes.It is intended to be a standards-based alternative to tools like Lotus ScreenCam.
sudo apt-get install xvidcap
Istanbul
Istanbul is a desktop session recorder for the Free Desktop. It records your session into an Ogg Theora video file. To start the recording, you click on its icon in the notification area. To stop you click its icon again. It works on GNOME, KDE, XFCE and others. It was named so as a tribute to Liverpool's 5th European Cup triumph in Istanbul on May 25th 2005.
sudo apt-get install istanbul
Vnc2Flv
Vnc2flv is a cross-platform screen recording tool for UNIX, Windows or Mac. It captures a VNC desktop session (either your own screen or a remote computer) and saves as a Flash Video (FLV) file.
Wink
Wink is a Tutorial and Presentation creation software, primarily aimed at creating tutorials on how to use software (like a tutor for MS-Word/Excel etc). Using Wink you can capture screenshots, add explanations boxes, buttons, titles etc and generate a highly effective tutorial for your users. It requires GTK 2.4 or higher and unfortunately is just a freeware(could not find any source code for it).
Screenkast
Screenkast is a screen capturing program that records your screen-activities, supports commentboxes and exports to all video formats.
If you got any more suggestions, please drop the comment. :)
Read more...
Bookmark this post: |
|
Wednesday, 18 July 2012
Why Alias Command With Itself
Aliasing the command to itself to suppress the original functionality of the command and provide it new added sets of functionality can come quite handy for linux users and administrators.
If you have been using linux shell for a while, I'm pretty sure you are now familiar with the `ls` command, if not I think you have just learnt to use man pages. Probably you've been using `ls -l` command to list files with the files size as well. Too bad, you won't just be able to instantly make the sense of the file size displayed using this command so why not alias `ls` command to always provide human readable file sizes. So here is my alias:
This is what I always want to see as the output with `ls` command. The same kind of alias can be used with `du` and `df` commands. There are number of other cases where aliasing a command with itself is good choice.
Another example is the less command. By default, you need to press q to exit less which can be quite annoying if the entire content can fit in a single screen. However, adding -F flag will gracefully quit after displaying the content if the content fits in a single screen. So I have my alias for less as below:
If something shoots in your mind, feel free to share here as a comment :)
Read more...
If you have been using linux shell for a while, I'm pretty sure you are now familiar with the `ls` command, if not I think you have just learnt to use man pages. Probably you've been using `ls -l` command to list files with the files size as well. Too bad, you won't just be able to instantly make the sense of the file size displayed using this command so why not alias `ls` command to always provide human readable file sizes. So here is my alias:
alias ls='ls -lh'
This is what I always want to see as the output with `ls` command. The same kind of alias can be used with `du` and `df` commands. There are number of other cases where aliasing a command with itself is good choice.
Another example is the less command. By default, you need to press q to exit less which can be quite annoying if the entire content can fit in a single screen. However, adding -F flag will gracefully quit after displaying the content if the content fits in a single screen. So I have my alias for less as below:
alias lesss='less -F'
If something shoots in your mind, feel free to share here as a comment :)
Read more...
Bookmark this post: |
|
Friday, 13 July 2012
Stack-based Directory Switching For Easy Reversal
So how many times have you used the `cd` command repeatedly to go back and forth of two or more directories. Probably you are already familiar to the `cd -` command which lets you switch between the current and the previous directory. But, many times this current and previous directory switching restriction will not suffice and hence a better option in such case is to use the `pushd` command instead of `cd`.
For example, just use the `pushd somedirA`, `pushd somedirB`, ... and like that. Now if you need to switch back, you can just use `popd` command and you'll be switching back easily. The `pushd` command saves the current directory path and then cds to the supplied path.
If you dig more, you'll come to know about the -n and -N switches you can combine with these commands so I will let you explore on this. Also, you can use the `dirs` command to view the stack of directories. If you are some computer student or enthusiast, you have already gotten an idea from a famous data structure called stack. Anyway, I hope this comes handy sometimes like it does to me :)
Read more...
For example, just use the `pushd somedirA`, `pushd somedirB`, ... and like that. Now if you need to switch back, you can just use `popd` command and you'll be switching back easily. The `pushd` command saves the current directory path and then cds to the supplied path.
If you dig more, you'll come to know about the -n and -N switches you can combine with these commands so I will let you explore on this. Also, you can use the `dirs` command to view the stack of directories. If you are some computer student or enthusiast, you have already gotten an idea from a famous data structure called stack. Anyway, I hope this comes handy sometimes like it does to me :)
Read more...
Bookmark this post: |
|
Friday, 15 June 2012
Recover Deleted Files From An NTFS Volume Using Ntfsundelete
Ntfsundelete is a part of ntfsprogs, a suite of NTFS utilities based around a shared library. It lets us recover the deleted files from any NTFS volumes without making any changes in the NTFS volume itself.
Generally when a file is deleted from disks, it is some kind of pointer to the physical file that gets deleted and the actual content still remains in the disk unless it is overwritten by new files so it is possible to recover those files.
ntfsundelete has three modes of operation: scan, undelete and copy. By default, it will run in the scan mode which simply reads an NTFS volume and looks for the files that have been deleted.
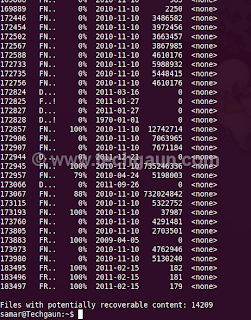
To use ntfsundelete, you'll have to install the ntfsprogs suite with following command in ubuntu and debian-based distros:
You'll have to first figure out which drive you want to recover. A handy command for this is:
Once you know the NTFS volume you want to recover, you can first run the scan mode to list the filenames that can be recovered.
The optional -f switch can be specified for the forceful scanning. There is a nice percentage field which gives the information on how much of the file can be recovered. You can apply the time and percentage filters to scan specific files. For example, you can use the following command to search for the files which can be recovered 100%
And, you can apply the time filter to list the files altered/deleted after the specified time. For example, following command will scan and list the files deleted in the last 14 days.
Other suffices you can use are d, w, m, y for days, weeks, months or years ago respectively.
Once you get the files to be recovered, you can use the -u switch to undelete or recover the files. An example of recovering files by pattern matching is as below:
Similarly you can recover by providing inode or inodes range using the -i switch. You can get the inode values from the first column in the scan mode.
Read more...
Generally when a file is deleted from disks, it is some kind of pointer to the physical file that gets deleted and the actual content still remains in the disk unless it is overwritten by new files so it is possible to recover those files.
ntfsundelete has three modes of operation: scan, undelete and copy. By default, it will run in the scan mode which simply reads an NTFS volume and looks for the files that have been deleted.

To use ntfsundelete, you'll have to install the ntfsprogs suite with following command in ubuntu and debian-based distros:
samar@Techgaun:~$ sudo apt-get install ntfsprogs
You'll have to first figure out which drive you want to recover. A handy command for this is:
samar@Techgaun:~$ sudo fdisk -l
Once you know the NTFS volume you want to recover, you can first run the scan mode to list the filenames that can be recovered.
samar@Techgaun:~$ sudo ntfsundelete /dev/sda4
The optional -f switch can be specified for the forceful scanning. There is a nice percentage field which gives the information on how much of the file can be recovered. You can apply the time and percentage filters to scan specific files. For example, you can use the following command to search for the files which can be recovered 100%
samar@Techgaun:~$ sudo ntfsundelete -p 100 /dev/sda4
And, you can apply the time filter to list the files altered/deleted after the specified time. For example, following command will scan and list the files deleted in the last 14 days.
samar@Techgaun:~$ sudo ntfsundelete -p 100 -t 2d /dev/sda4
Other suffices you can use are d, w, m, y for days, weeks, months or years ago respectively.
Once you get the files to be recovered, you can use the -u switch to undelete or recover the files. An example of recovering files by pattern matching is as below:
samar@Techgaun:~$ sudo ntfsundelete -u -m *.jpg /dev/sda4
Similarly you can recover by providing inode or inodes range using the -i switch. You can get the inode values from the first column in the scan mode.
samar@Techgaun:~$ sudo ntfsundelete -u -i 161922 /dev/sda4
Read more...
Bookmark this post: |
|
Monday, 11 June 2012
Graphical Frontends To Sopcast Client For Linux
As all of you know the official Sopcast client for linux is only the command line version and many people find it difficult to use the CLI version. However, many good people have made an effort to write the graphical frontends to the Sopcast client for linux. Here you will find some of such GUI frontends for sopcast.
Sopcast Player: SopCast Player is designed to be an easy to use Linux GUI front-end for the p2p streaming technology developed by SopCast. SopCast Player features an integrated video player, a channel guide, and bookmarks. Once SopCast Player is installed it simply "just works" with no required configuration.
qsopcast: qsopcast is a QT GUI front-end of the Linux command line executive of P2P TV sopcast.
gsopcast: gsopcast is a GTK based GUI front-end for p2p TV sopcast.
TV-Maxe: TV-MAXE is an application which provides the ability to watch TV stations and listen radio via different streams, such is SopCast. Currently it has a large number of channels, both romanian and international.
SCPlayer: SCPlayer is a simple and lightweight GUI frontend for sopcast supporting only linux GNOME3 platform.
Pysopcast: It is a simple GUI for sopcast made using PyGTK.
totem-sopcast: A totem plugin to let you browse and play sopcast streams.
wxsopcast: A sopcast GUI for linux written in python and wxPython. Note that the channel URL needs to be changed to http://www.sopcast.com/gchlxml at first.
jsopcast: jsopcast is a simple GUI to see P2P TV sopcast made in Java.
If you know of any other GUI frontend for sopcast, please feel free to leave a comment. :)
Read more...
Sopcast Player: SopCast Player is designed to be an easy to use Linux GUI front-end for the p2p streaming technology developed by SopCast. SopCast Player features an integrated video player, a channel guide, and bookmarks. Once SopCast Player is installed it simply "just works" with no required configuration.
qsopcast: qsopcast is a QT GUI front-end of the Linux command line executive of P2P TV sopcast.
gsopcast: gsopcast is a GTK based GUI front-end for p2p TV sopcast.
TV-Maxe: TV-MAXE is an application which provides the ability to watch TV stations and listen radio via different streams, such is SopCast. Currently it has a large number of channels, both romanian and international.
SCPlayer: SCPlayer is a simple and lightweight GUI frontend for sopcast supporting only linux GNOME3 platform.
Pysopcast: It is a simple GUI for sopcast made using PyGTK.
totem-sopcast: A totem plugin to let you browse and play sopcast streams.
wxsopcast: A sopcast GUI for linux written in python and wxPython. Note that the channel URL needs to be changed to http://www.sopcast.com/gchlxml at first.
jsopcast: jsopcast is a simple GUI to see P2P TV sopcast made in Java.
If you know of any other GUI frontend for sopcast, please feel free to leave a comment. :)
Read more...
Bookmark this post: |
|
Subscribe to:
Posts (Atom)